Improving ARP performance on slow AX.25 links
Recently I’ve been setting up TCP/IP connections over VHF radio. They are Linux systems linked by 1200 baud AX.25 modems. Opinions vary as to whether the overheads of TCP/IP are worthwhile at 1200 baud—9600 is certainly better—but it’s handy and it definitely works provided you use the available bandwidth carefully. All IP communications need to be precise and tidy. Otherwise the channel gets gummed up for seconds at a time and it’s not much fun to use.
Using Debian/Raspbian one of the most obvious problems is ARP traffic. When I watch the channel with axlisten I see huge quantities of requests and replies flying past, maintaining associations between callsigns like “VK7NTK-1” and IP addresses like 44.136.224.30*.
At home I have two separate computers and radios set up to talk to each other. With nothing in the ARP cache, if I run ping -c 1 44.136.224.30 I would naively expect to see something like the following. It’s basically like Ethernet except instead of MAC addresses there are callsigns and SSID numbers.

First the pinging station finds out who owns the IP; then it sends the ping. Aah, if only.
Problem 1: Duplicate ARP requests
Using a default ARP configuration the transmissions actually turn out like this:

At 1200 baud it takes most of a second to transmit even the shorter packets. The modems also check that the channel is clear before transmitting, introducing additional delays. As a result, after VK7NTK-2 decided it needed to do an ARP query the other computer didn’t even finish receiving it until 0.8 seconds later. VK7NTK-1 transmitted its reply, taking another 0.7 seconds, so VK7NTK-2 had the address it needed about 1.5 seconds after its initial request. Unfortunately at the 1 second mark it decided that the first request had been lost and queued a second query for transmission.
When that first reply did come back at 1.5 seconds VK7NTK-2 realised it had the information it needed to do the ping so it created the ICMP packet and queued that for delivery too. At that point it had two packets to transmit: the second ARP query, now unnecessary, and the ping request. In this case the modem decided to transmit them back-to-back, which is allowed.
VK7NTK-1 received both of these and queued up a reply to each one. These were also transmitted back-to-back and the ping ultimately succeeded.
The basic problem is that 1 second is far too short a timeout for ARP requests at 1200 baud. Linux isn’t clever enough to cancel the second ARP query when it’s no longer needed so I end up with an entire extra request and reply.
But wait, there’s more! Several seconds after the ping there is suddenly an ARP query in the other direction, originating from the computer that received the ping. I’m guessing this is an optimisation in Linux to warm up the ARP cache in advance. This one was even messier:
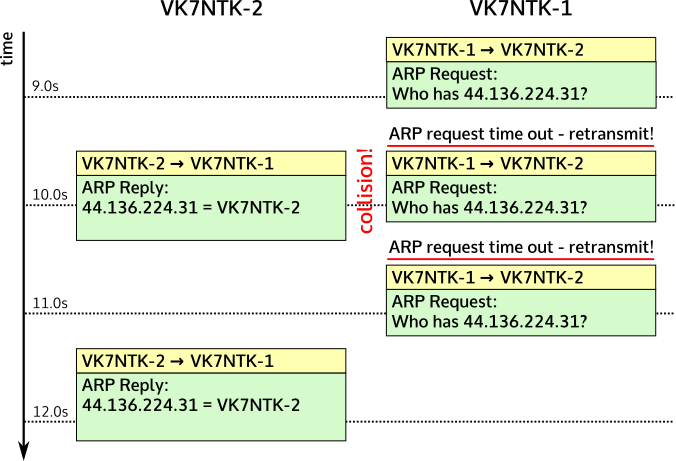
In total VK7NTK-1 transmitted three ARP requests and VK7NTK-2 transmitted two ARP replies. Two of those transmissions doubled—that is, both modems thought the channel was clear and started transmitting simultaneously. VK7NTK-1 didn’t receive the answer it wanted because it was too busy shouting the question over the top.
This is also caused by the 1 second timeout but in a different way. If you send out a query that takes 3/4 of a second to transmit, then add a little time for processing and making sure the channel is clear, you would assume that the reply will begin at about the 1 second mark. For the sender of the query, 1 second later is about the worst possible time to make a second transmission, regardless of whether it has anything to do with the previous one. You’re just asking for a double.
Solution 1. Adjust the the ARP retransmission time
The good news is that Linux makes it easy to change the ARP retransmission time. The following command increases it from the default 1 second to 5 seconds:
echo 5000 > /proc/sys/net/ipv4/neigh/ax0/retrans_time_ms
I placed this in a script that runs after the ax0 interface is configured. It solves both of the above problems fine.
Problem 2: The forgetful cache
After all the nonsense they went through exchanging ARP packets it would be nice if Linux remembered the results for a while. Unfortunately it doesn’t. It’s slightly randomised but roughly 15 seconds later the ARP entry will change from “REACHABLE” to “STALE”. A subsequent ping will cause the whole schmozzle to happen again. It wouldn’t be a big deal on zippy Ethernet but it really is on 1200 baud.
You can check the state of ARP entries using this command:
# ip -s neighbor list
...
44.136.224.31 dev ax0 lladdr ac:96:6e:9c:a8:96:04 used 3411/3404/3242 probes 1 STALE
Solution 2: Increase the reachable time
This is another parameter that’s easy to control. To have 10+ minutes in the REACHABLE state:
echo 1200000 > /proc/sys/net/ipv4/neigh/ax0/base_reachable_time_ms
The best solution: static ARP entries
Unlike Ethernet where most people are using DHCP and changing addresses semi-regularly, AX.25 stations tend to have pretty fixed addresses. Adding a permanent ARP entry means that Linux never makes any requests at all for that station.
I use this command to add an entry for my upstream gateway VK7HDM-6:
arp -H ax25 -s 44.136.224.32 VK7HDM-6
It is still good to have the other optimisations in place for stations that come and go.
*The problem looks slightly worse than it is because axlisten (or arguably the kernel) is a little buggy. The obsolete AF_INET raw interface seems to report duplicates of some frames. I have confirmed with my own software that the newer AF_PACKET/SOCK_RAW interface works fine. See manpage packet(7).
P.S. The very nature of doubled transmissions is that the computers don’t really know what’s going on and Wireshark gives misleading results. An iPad clock and phone video are a low-tech but dependable way to observe sub-second collisions.
